-
- Mod 3 - Multiple Reg
- 3.1 Overview
- 3.2 The Model
- 3.3 Assumptions
- 3.4 Modelling LSYPE Data
- 3.5 Model 1: Ordinal Explanatory Variables
- 3.6 Model 2: Dichotomous Explanatory Variables
- 3.7 Model 3: Nominal Variables
- 3.8 Predicting Scores
- 3.9 Model 4: Refining the Model
- 3.10 Comparing Coefficients
- 3.11 Model 5: Interaction Effects 1
- 3.12 Model 6: Interaction Effects 2
- 3.13 Model 7: Value Added Model
- 3.14 Diagnostics and Assumptions
- 3.15 Reporting Results
- Quiz
- Exercise
- Mod 3 - Multiple Reg
Using Statistical Regression Methods in Education Research

3.9 Refining the Model: Treating Ordinal Variables as Dummy Variables (Model 4)
|
So far we have treated SEC as a continuous variable or scale. What are the implications of having done this? Treating a variable as a scale means that any case with a missing value on the variable is lost from the analysis. The frequency table for SEC was shown in Figure 3.4.2. A total of 2941 cases (18.6%) were missing a value for SEC, which is a high level of data loss. One way of coping with this is to recode SEC into dummy variables, as we did with ethnic group (Page 3.7
We used the following syntax to change SEC into a series of dummy variables: Creating dummy variables for SEC
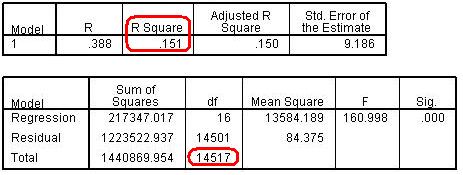
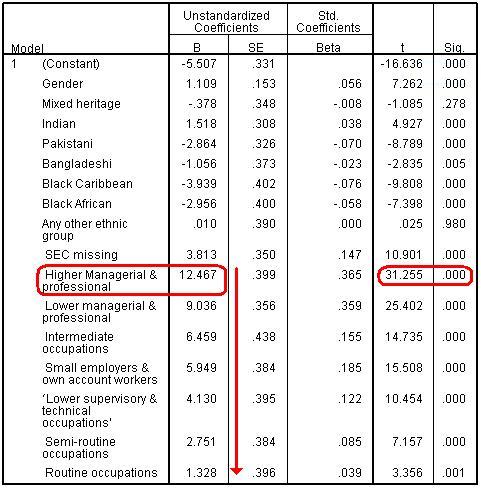
Repeat the regression we did on Page 3.7 Figure 3.9.1 presents the model summary and the ANOVA table. From the Model Summary we see that the model r2 is 15.1%. This is lower than for model 3 where the model accounted for 17.0% of the variance. However this reflects two factors: the change from treating SEC as a scale variable to modelling it as a set of dummy variables and the increase in sample size associated with including the previously omitted 2,900 or so cases. We can see from the ANOVA table that we are including 14,518 cases in this analysis (the total df shows the number of cases - 1), rather than the 12,100 cases included in model 3. We will not pursue the relative contribution of these two factors here, since the increase in sample size is reason enough for preferring the treatment of SEC as a set of dummy variables. Figure 3.9.1: model summary and the ANOVA table Figure 3.9.2 shows the regression coefficients from the model. Figure 3.9.2: Regression coefficients for Model 4 As we saw before, there is clearly a strong relationship between SEC and age 14 attainment, even after accounting for gender and ethnicity. Breaking the SEC variable down into its individual categories and comparing them to the base category of ‘long term unemployed’ makes interpretation of the coefficients more intuitive. For example, students from ‘Higher managerial and professional’ homes are predicted to obtain 12.5 more standard score marks than those from homes where the main parent is long term unemployed. Students from ‘lower managerial and professional’ homes achieve 9.0 more marks, those from intermediate homes 6.5 more marks and so on. You can see the ordinality in the data from the decreasing B coefficients: as the SEC of the home decreases there is a reduction in the extent of the ‘boost’ to age 14 standard score above the reference group of students from homes where the head of the household is long term unemployed. Being able to interpret the difference between categories in this way is very useful! We can see from the t statistic and associated ‘sig’ values that all SEC contrasts are highly statistically significant, including for those students with missing values for SEC. |