Using Statistical Regression Methods in Education Research

1.3 Quantitative Research
|
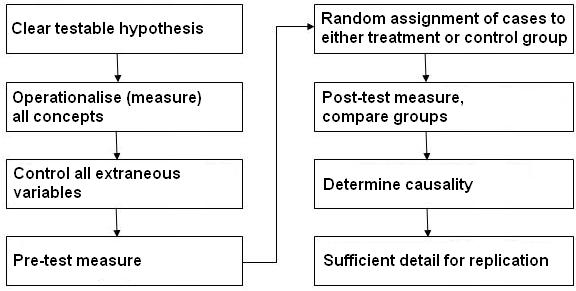
This website does not aim to provide an in depth discussion about research methods as there are comprehensive alternative sources available if you want to learn more about this (check out our Resources page Experimental designs: Experimental designs are highly regarded in many disciplines and are related to experiments in the natural sciences (you know the type - where you nearly lose your eyebrows due to some confusion about whether to add the green chemical or the blue one). The emphasis is on scientific control, making sure that all the variables are held constant with the exception of the ones you are altering (independent variable) and the ones you are measuring as outcomes (dependent variable). Figure 1.3.1 illustrates the type of process you may take: Figure 1.3.1: The process of experimental research
A Quasi-experiment is one where truly random assignment of cases to intervention or to control groups is not possible. For example, if you wanted to examine the impact of being a smoker on performance in a Physical Education exam you could not randomly assign individuals into ‘smoking’ and ‘non-smoking’ groups – that would not be ethical (or possible!). However you could recruit individuals who are already smokers to your experimental group. You could control for factors like age, SEC, gender, marital status (anything you think might be important to your outcome) by matching your ‘smoking’ participants with similar ‘non-smoking’ participants. This way you compare two groups that were matched on key variables but differed with regard to your independent variable – whether or not they smoke. This is imperfect as there may be other factors (confounding variables) that differ between the groups but it does allow you to use a form of experimental design in a natural context. This type of approach is more common in the social sciences where ethical and practical concerns make random allocation of individuals problematic. Non-experimental designs: These designs gather substantial amounts of data in naturally occurring circumstances, without any experimental manipulation taking place. At one level the research can be purely descriptive (e.g. what is the relationship between ethnicity and student attainment?). However with careful selection and collection of data and appropriate analytic methods, such designs allow the use of statistical control to go beyond a purely descriptive approach (e.g. can the relationship between ethnicity and attainment be explained by differences in socio-economic disadvantage?). By looking at relationships between the different variables it can be possible for the researcher to draw strong conclusions that generalise to the wider population, although conclusions about causal relationships will be more speculative than for experimental designs. For example, secondary schools differ in the ability of their students on intake at age 11 and this impacts very strongly on the pupils attainment in national exams at age 16. As a result ‘raw’ differences in exam results at age 16 may say little about the effectiveness of the teaching in a given school. You can’t directly compare grammar schools to secondary modern schools because they accept students from very different baseline levels of academic ability. However if you control for pupils’ attainment at intake at age 11 you can get a better measure of the school’s effect on the progressof pupils. You can also use this type of statistical control on other variables that you feel are important such as socio-economic class (SEC), ethnicity, gender, time spent on homework, attitude to school, etc. All of this can be done without the need for any experimental manipulation. This type of approach and the statistical techniques that underlie it are the focus of this website.
In some ways we don’t really like to use the term ‘quantitative methods’ as it somehow suggests that they are totally divorced from ‘qualitative methods’. It is important to avoid confusing methods with data. As Figure 1.3.2 suggests, it is more accurate to use the terms ‘quantitative’ and ‘qualitative’ to describe data rather than methods, since any method can generate both quantitative and qualitative data. Figure 1.3.2: Research methods using different types of data
You may be conducting face-to-face interviews with young people in their own homes (as is the case in the dataset we are going to use throughout these modules) but choose a highly structured format using closed questions to generate quantitative data because you are striving for comparable data across a very large sample (15,000 students as we shall see later!). Alternatively you may be interested in a deep contextualised account from half a dozen key individuals, in which case quantitative data would be unlikely to provide the necessary depth and context. Selecting the data needed to answer your research questions is the important thing, not selecting any specific method.
The hallmark of quantitative research is measurement - we want to measure our key concepts and express them in numerical form. Some data we gather as researchers in education are directly observable (biological characteristics, the number of students in a class etc.), but most concepts are unobservable or ‘latent variables’. For any internal mental state (anxiety, motivation, satisfaction) or inferred characteristic (e.g. educational achievement, socio-economic class, school ethos, effective teachers etc) we have to operationalise the concept, which means we need to create observable measures of the latent construct. Hence the use of attitude scales, checklists, personality inventories, standardised tests and examination results and so on. Establishing the reliability and validity of your measures is central but beyond the scope of this module. We refer you to Muijs (2004) for a simple introduction and any general methods text (e.g. Cohen et. al., 2007, Newby, 2009) for further detail.
The construct we have collected data on is usually called the variable (e.g. gender, IQ score). Particular numbers called values are assigned to describe each variable. For example, for the variable of IQ score the values may range from 60-140. For the variable gender the values may be 0 to represent ‘boy’ and 1 to represent ‘girl’, essentially assigning a numeric value for each category. Don’t worry, you’ll get used to this language as we go through the module!
As we have said, the hallmark of quantitative research is measurement, but not every measurement is equally precise: saying someone is ‘tall’ is not the same as saying someone is 2.0 metres. Figure 1.3.3 shows us that quantitative data can come in three main forms: continuous, ordinal and nominal. Figure 1.3.3: Levels of quantitative measurement
All of these levels of data can be quantified and used in statistical analysis but must usually be treated slightly differently. It is important to learn what these terms mean now so that they do not return to trip you up later! Field (2009), pages 7-10 discusses the types of data further (see the Resources |