-
- Mod 4 - Log Reg
- 4.1 Overview
- 4.2 Odds, Odds Ratios and Exponents
- Quiz A
- 4.3 A General Model
- 4.4 Log Reg Model
- 4.5 Logistic Equations
- 4.6 How good is the model?
- 4.7 Multiple Explanatory Variables
- 4.8 Methods of Log Reg
- 4.9 Assumptions
- 4.10 Example from LSYPE
- 4.11 Log Reg on SPSS
- 4.12 SPSS Log Reg Output
- 4.13 Interaction Effects
- 4.14 Model Diagnostics
- 4.15 Reporting the Results
- Quiz B
- Exercise
- Mod 4 - Log Reg
Using Statistical Regression Methods in Education Research

4.14 Model Diagnostics
|
On Page 4.9
This assumption is confusing but it is not usually an issue. Problems with the linearity of the logit can usually be identified by looking at the model fit and pseudo R2 statistics (Nagelkerke R2, see Page 4.12 - Figure 4.12.4). The Hosmer and Lemeshow test, which as you may recall was discussed on Page 4.12 Figure 4.14.1: Hosmer and Lemeshow Test
With regard to the Nagelkerke R2 you are really just checking that your model is explaining a reasonable amount of the variance in the data. Though in this case the value of .159 (about 16%) is not high in absolute terms it is highly statistically significant.
Of course this approach is not perfect. Field (2009, p.296, see Resources
As we mentioned on Page 4.9
It is important to know how to perform the diagnostics if you believe there might be a problem. The first thing to do is simply create a correlation matrix and look for high coefficients (those above .8 may be worthy of closer scrutiny). You can do this very simply on SPSS: Analyse > Correlate > Bivariate will open up a menu with a single window and all you have to do is add all of the relevant explanatory variables into it and click OK to produce a correlation matrix.
If you are after more detailed colinearity diagnostics it is unfortunate that SPSS does not make it easy to perform them when creating a logistic regression model (such a shame, it was doing so well after including the ‘interaction’ button). However, if you recall, it is possible to collect such diagnostics using the menus for multiple linear regression (see Page 3.14
On page 4.11
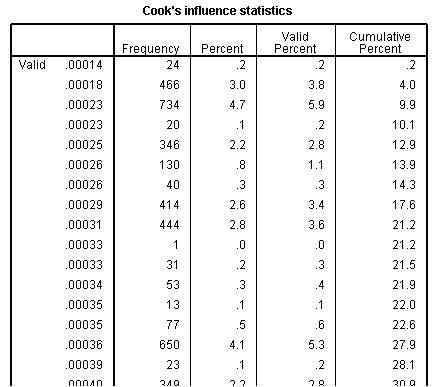
Figure 4.14.2: Frequency of Cook’s distance for model
This is not so bad though – remember we are looking for values greater than one and these values are in order. If you scroll all the way to the bottom of the table you will see that the highest value Cook’s distance is less than .014… nowhere near the level of 1 at which we need to be concerned.
Finally we have reached the end of our journey through the world of Logistic Regression. Let us now take stock and discuss how you might go about pulling all of this together and reporting it. |
 ).
).