-
- Mod 3 - Multiple Reg
- 3.1 Overview
- 3.2 The Model
- 3.3 Assumptions
- 3.4 Modelling LSYPE Data
- 3.5 Model 1: Ordinal Explanatory Variables
- 3.6 Model 2: Dichotomous Explanatory Variables
- 3.7 Model 3: Nominal Variables
- 3.8 Predicting Scores
- 3.9 Model 4: Refining the Model
- 3.10 Comparing Coefficients
- 3.11 Model 5: Interaction Effects 1
- 3.12 Model 6: Interaction Effects 2
- 3.13 Model 7: Value Added Model
- 3.14 Diagnostics and Assumptions
- 3.15 Reporting Results
- Quiz
- Exercise
- Mod 3 - Multiple Reg
Using Statistical Regression Methods in Education Research

3.12 Exploring Interactions Between Two Nominal Variables (Model 6)
|
The above process is relatively easy to compute (yes, I’m afraid it will get a little harder below!) but has the same problem of data loss we identified earlier. The 2941 cases that have no valid value for SEC are excluded from the model. As before we can avoid this data loss if we transform SEC to a set of dummy variables and explicitly include missing values as an additional dummy variable. This has the advantages outlined on Page 3.8
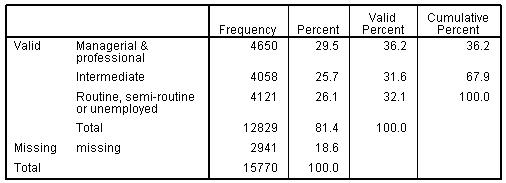
The Office for National Statistics socio-economic class (NS-SEC) coding system was used in this study. The system includes criteria for identifying 8, 5 or 3 class versions of SEC (see Resources All of the variables and interaction terms over the rest of this page have already been created for you in the MLR LSYPE 15000 The new variable looks like this: Figure 3.12.1: Frequencies for collapsed SEC variable
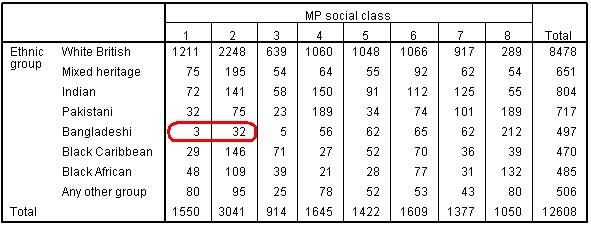
We can then calculate dummy variables for the collapsed variable, taking category 3 (low SEC) as the base or reference category. The dummy variables are already in the dataset and we have already shown you how to create dummy variables on Page 3.7 We should note that collapsing a variable is not only useful if we want to test interactions, it is most often necessary where the number of cases in a cell is particularly low. Figure 3.12.2 shows the Crosstabulation of SEC and ethnic group. We can see there were only three Bangladeshi students in SEC class 1. By combining SEC classes 1 and 2 we increase the number of Bangladeshi students in the high SEC cell to 35. This is still relatively low compared to other ethnic groups, but will provide a more robust estimate than previously. Figure 3.12.2: Crosstabulation of SEC by ethnic group
As before to create the interaction terms we simply multiply each ethnic dummy variable by the relevant SEC dummy variable. Again, we have done this for you in the MLR LSYPE 15000
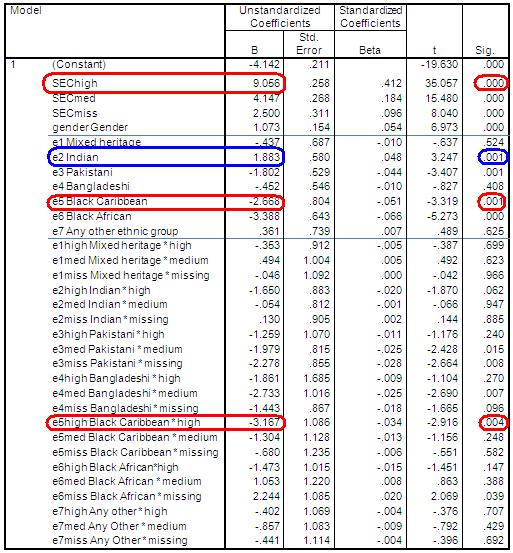
Now we can see the relationship between ethnic group, SEC and attainment using the full sample of students. Run the regression analysis including all main and interaction variables: ks3stand (Dependent), SEChigh, SECmed, SECmiss, gender, e1-e7 and all interaction terms (e.g. e1high, e1med, e1miss, e2high, e2med, e2miss, etc. Twenty-one terms in total). Remember to request predicted values from the SAVE submenu (which will be saved by default to the variable PRE_3 because this is the third time we have asked SPSS to save predicted values). Figure 3.12.3 shows the coefficient output. Figure 3.12.3: Regression coefficients output for Model 6 The output initially might look a little overwhelming as there are a considerable number of variables included, but this is still small compared to many models! We’re not sure if that is reassuring or not... The good thing is that the interpretation of the output is substantially the same as we saw on Page 3.11
As before a good way of interpreting this data is to calculate what the predicted age 14 standard scores are from the model.
Predicted age 14 score for White British boys from high SEC homes: As White British boys are the reference group this value will be calculated from just two terms: intercept + high SEC coeff. Ŷ = -4.142 + 9.056 = 4.914
Predicted age 14 score for Black Caribbean boys from high SEC homes: This will be calculated from: intercept + Black Caribbean coeff. + high SEC coefficient + Black Caribbean*High interaction coeff. Ŷ = -4.142 + -2.668 + 9.056 + -3.167 = -.921
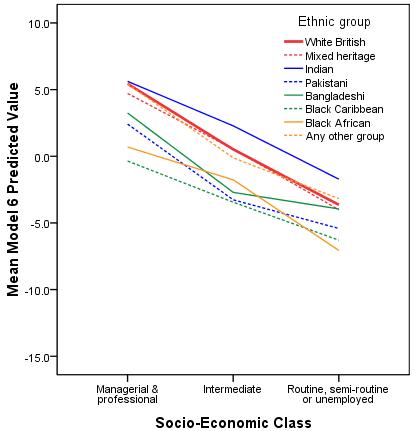
Note that gender is just modelled as a main effect (it has not been allowed to interact with SEC or ethnic group), so you would just add 1.073 to get the predicted values for girls from any ethnic or SEC group. Again we can plot the predicted value that we saved earlier when we specified the regression model (the values were saved as the variable PRE_3). NOTE: For the purpose of plotting this graph we have excluded the cases where SEC was missing by first setting the missing values code for SECshort to 0 (remember 0 indicated missing values). If you want to know how we did this, view the syntax below: SYNTAX ALERT! MISSING VALUES secshort(0). GRAPH /LINE(MULTIPLE)MEAN(pre_3) BY secshort by Ethnic. If you prefer, you can use the Select Cases option.
Figure 3.12.4: Predicted values for attainment at age 14 including interactions between ethnic group and SEC (Both coded as dummy variables)
There are significant interactions between the Pakistani and Bangladeshi groups and medium SEC (p=.015 and p=.007 respectively) and between Black Caribbean and high SEC (p=.004). The effects are not only statistically significant they are also quite large, as can be seen in Figure 3.12.4. Note here that the regression lines are no longer parallel because we have allowed for different slopes in our regression model. The slope for White British students is significantly steeper than for most ethnic minority groups indicating the differences between high SEC and low SEC homes is particularly pronounced for White British students. Looking at the coefficients in Figure 3.12.3 we see that the differences between ethnic groups from lower SEC homes are much smaller than the differences among high SEC homes. Note that the significance tests for the ethnic group coefficients in the SPSS output are for ethnic differences in the reference group of low SEC homes. If we want to test the significance of the ethnic group differences in high SEC homes we can just change our reference group to high SEC. Similarly if we want to test the significance of the ethnic difference at medium SEC we could change reference group to Medium SEC.
Again we can test whether we have significantly improved the r2 by entering the variables in two blocks and calculating the r2 change (see Page 3.11 Figure 3.12.5: Model summary and change statistics for Model 6
In Figure 3.12.5, which we received as part of our regression output, we are interested here in the columns headed ‘Change Statistics’ and specifically in the second row which compares Block 2 (the interaction model) against Block 1 (the main effects model). We can see that the increase in r2 for the interaction model, while small at 0.2%, is highly statistically significant (p = .005). So while the increase in overall r2 is small, the model with interactions gives a significantly better fit to the data than we get if the interactions are not included. |
 , so you do not need to create them yourself. However, if you would like to follow the process exactly then feel free! You can either use the Recode menu (see
, so you do not need to create them yourself. However, if you would like to follow the process exactly then feel free! You can either use the Recode menu (see