top
To illustrate some analyses on the weighted data, we have
selected a sub-group of the population that is of particular
interest to the Health Board. This is the group of young
women aged 16-29, and their drug use is of particular
interest. Because this survey is neither clustered not
stratified we can analyse this subgroup without reference to
the rest of the survey. Also, we saw above that the largest
factor affecting weighting was age group. So we might expect
the weighting here to have only a minor effect.
These are non-response weights rather than design weights
(seesection 3.9 in the
theory section for a discussion of this). They are
probability weights, so the design-based procedures can be
used for inference, although they will not incorporate the
uncertainty due to modelling the non response.
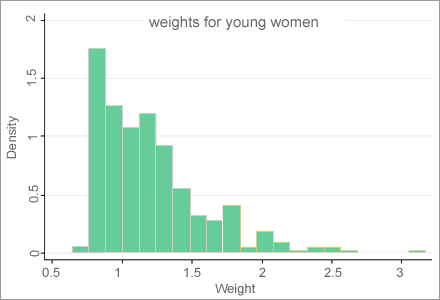
There were only 361 young women in the survey and the
range of their weights was considerably less than for the
whole survey (see Figure 5.4 below).
Figure 5.4 Weights for
young women
We can see in Table 5.4 that
the weighted and unweighted proportions for categorical
variables differ by very little.
General Health
(score)
|
Unweighted |
Weighted |
Cannabis Use
(score)
|
Unweighted |
Weighted |
|
Excellent (5)
|
20%
|
19%
|
Daily (1)
|
3%
|
3%
|
|
Very good (4)
|
39%
|
38%
|
Weekly (1)
|
2%
|
2%
|
|
Good (3)
|
33%
|
34%
|
Last month (1)
|
3%
|
3%
|
|
Fair (2)
|
7%
|
7%
|
More than a
month ago (0.5)
|
7%
|
8%
|
|
Poor (1)
|
2%
|
2%
|
Onceor twice (0)
|
25%
|
25%
|
|
|
|
Never (0)
|
59%
|
58%
|
Table 5.4 Weighted and
unweighted proportions for General Health groups and Cannabis
Use groups for young women
By looking at the means of some of these
variables, scored as shown above, we can also see that the
 design effects
are quite modest for this sub-group of the survey
although of course they vary by what is being measured (Table
5.5). . If there had been no relationship between a variable
and the weight the design effect could be calculated from the
weights (see
weighting section 3.7) here because there is no
stratification or clustering. For this example it would give
a Design Effect of 1.10. we can see that the income score,
that we know to be related to the weights, has a larger
design effect although its size is quite modest. design effects
are quite modest for this sub-group of the survey
although of course they vary by what is being measured (Table
5.5). . If there had been no relationship between a variable
and the weight the design effect could be calculated from the
weights (see
weighting section 3.7) here because there is no
stratification or clustering. For this example it would give
a Design Effect of 1.10. we can see that the income score,
that we know to be related to the weights, has a larger
design effect although its size is quite modest.
| � |
mean |
s.e. |
lower limit |
upper limit |
design effect |
|
General health
|
2.36
|
0.05
|
2.26
|
2.47
|
1.14
|
|
SIMD income score
|
18.71
|
0.69
|
17.35
|
20.08
|
1.31
|
|
SIMD access score
|
-0.07
|
0.03
|
-0.13
|
0.00
|
1.04
|
Table 5.5 Design effect
for estimated mean of three variables, for young women
A finite population
correction was used in the analysis here. It made almost
no difference, changing the standard error
for general health from 0.0527406 to 0.052416. The
same was true when regression models were fitted to the
relationship between variables. Details can be found in the
programs and output for this exemplar. We show below some
results for survey weighted regressions predicting the health
score from various factors. the Health score and drug use
were scored according to values given on table 5.4 above.
| predictor |
|
model 1 |
model 2 |
model 3 |
model 4 |
model 5 |
model 6 |
model 7 |
Cannabis
score
|
coefficent |
0.455 |
|
|
0.44 |
|
0.509 |
0.51 |
| t statistic |
(3.03)** |
|
|
(2.92)** |
|
(3.38)** |
(3.47)** |
Amphetamine
score
|
coefficient |
|
0.302 |
|
|
0.285 |
0.247 |
0.23 |
| t statistic |
|
-1.86 |
|
|
(2.03)* |
(2.08)* |
(2.37)* |
Income
deprivation
|
coefficient |
|
|
0.015 |
0.013 |
0.013 |
|
0.013 |
| t statistic |
� |
|
(2.85)** |
(2.52)* |
(2.63)** |
|
(2.66)** |
| Observations |
|
358 |
338 |
361 |
358 |
338 |
338 |
338 |
| *significant at 5%
level; **significant at 1% level
|
5.5 Prediction of geneal
health score weighted regression
We can see that poor health is associated
with income deprivation and independently with both cannabis
use and amphetamine use. Of course we cannot tell from this
analysis whether drug use causes poor health rating or
vice-versa, or whether it is some other factor that is
responsible for the association.
The unweighted regression gives broadly similar results, but
the association between amphetamine use and poor reported
health is not so clear-cut in the unweighted analysis. This
suggests that failing to weight can sometimes obscure
associations that should have been seen in the data.
| Predictor |
|
model 1 |
model 2 |
model 3 |
model 4 |
model 5 |
model 6 |
model 7 |
Cannabis
score
|
coeffecient |
0.455 |
|
|
0.44 |
|
0.509 |
0.51 |
| t statistic |
(3.03)** |
|
|
(2.92)** |
|
(3.38)** |
(3.47)** |
Amphetamine
score
|
coefficient |
|
0.302 |
|
|
0.285 |
0.247 |
0.23 |
| t statistic |
|
-1.86 |
|
|
(2.03)* |
(2.08)* |
(2.37)* |
Income
deprivation
|
coefficient |
|
|
0.015 |
0.013 |
0.013 |
|
0.013 |
| t statistic |
|
|
(2.85)** |
(2.52)* |
(2.63)** |
|
(2.66)** |
| Observations |
|
358 |
338 |
361 |
358 |
338 |
338 |
338 |
| * significant at 5%
level; **significant at 1% level
|
5.5 Prediction of geneal
health score unweighted regression
The exemplars also give analyses of the data
above using chi-squared tests, adjusted for weighting. They
do not show the same associations as did the regression
because they do not focus on the linear-by-linear
interaction. Their power is reduced by the fact that they are
seeking any association between a large number of cells. The
regression is more appropriate for this type of analysis with
such limited numbers. But the comparisons of chi squared
statistics in the exemplars does show how the design affects
these.
Effectively, all the packages features on
this site can do these analyses. SAS version 8 does not
include chi-squared tests for surveys, but version 9 will.
Similarly SPSS does not do regression for surveys, but
version 13 will.
The case to go to all this trouble here must
be at least marginal. The design effects
are all pretty small and none of the analyses we
have looked at are substantially different between the
weighted and unweighted analysis. Some other variables may be
more affected by this than the ones we have investigated. But
we have not looked at the whole survey, only a subgroup, so
it would be safer to use analyses that allow appropriately
for the weighting.
The largest factor affecting the weights was
age group. It is important to get the weighting right to
avoid bias in summaries for the whole population. Regression
analyses that adjust for age could probably be safely carried
out without weighting.
|