The formula for the
 standard error
standard error for the mean of a
simple random sample is well-known,
the standard formula being:
where 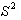 is the population variance and
n is the sample size. Having calculated the standard
errors, the 95% confidence interval for the mean is then
calculated as:
is the population variance and
n is the sample size. Having calculated the standard
errors, the 95% confidence interval for the mean is then
calculated as:
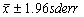 (or more
simply just use 2 SE's.)
(or more
simply just use 2 SE's.)
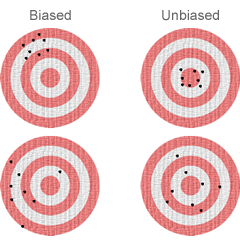
Simple random samples are relatively rare in practice for
most surveys we need an amended version of the basic
formula:
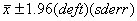 .
.
This equation also applies to other estimators, such as
proportions, regression coefficients. We can consider
proportions as the means of 0/1 variables so that the
expression for becomes P (1-P) where P is the population proportion.
The multiplier ‘deft’ in the above equation is
the ‘design factor’. The deft is essentially a
factor that adjusts the standard error because of design
features.
These features include:
(i) Stratification of the sample either to guarantee that
sub-groups appear in the correct proportions (proportionate
stratification) or to over-sample sub-groups (disproportionate
stratification).
(ii) Weighting of the sample to adjust for non equal
probabilities of selection.
(iii) Weighting of the sample to adjust for non-response.
(iv) Clustering of the
sample.
Generally speaking:
(i) proportionate stratification usually reduces the standard
error, giving a design factor of less than 1;
(ii) disproportionate stratification and sampling with
non-equal probabilities of selection tends to increase
standard errors, giving a design factor greater than 1. The
exception would be a survey that deliberately over sampled
that part of a population where the item of interest is
either very rare or very variable.
(iii) non-response weighting sometimes increases standard
errors and sometimes decreases them, although the impact
tends to be fairly small. So for non-response weights the
design factors may be less or greater than 1, but will
generally be reasonably close to 1;
(iv) clustering of the sample almost always increases
standard errors, giving a design factor greater than 1. The
size of the design factor depends on the cluster size and the
cluster homogeneity. The square of the design factor is the
‘design effect (deff)’. Whereas the deft is the
standard error multiplier, the deff is the variance
multiplier. Most software packages that deal with complex
surveys tend to give the deff rather than the deft.
Programs that use methods for complex
surveys will calculate the standard errors correcty, allowing
for the design. They will often produce design effects to
allow you to compare the survey to what would have been
obtained with a simple random sample. Some surveys come with
a few tables of design effects or factors to allow adjustment
of standard errors when methods for simple random samples are
used. See below for comments on
this.
The design factor (deft) is more useful for adjusting
standard errors. But the design effect tells you how much
information you have gained or lost by using a complex survey
rather than a simple random sample. A design effect of 2
means that you would need to have a survey that is twice the
size of a simple random sample to get the same amount of
information. Whereas a design effect of 0.5 means that you
would gain the precision from a complex survey of only half
the size of a simple random sample. Design effects of 2 are
quite common, but those of 0.5 are rare.