Using Statistical Regression Methods in Education Research

2.5 Simple Linear Regression
|
If you are wrestling with all of this new terminology (which is very common if you're new to stats, so don't worry!) then here is some good news: Regression and correlation are actually fundamentally the same statistical procedure. The difference is essentially in what your purpose is - what you're trying to find out. In correlation we are generally looking at the strength of a relationship between two variables, X and Y, where in regression we are specifically concerned with how well we can predict Y from X. Examples of the use of regression in education research include defining and identifying under achievement or specific learning difficulties, for example by determining whether a pupil's reading attainment (Y) is at the level that would be predicted from an IQ test (X). Another example would be screening tests, perhaps to identify children 'at risk' of later educational failure so that they may receive additional support or be involved in 'early intervention' schemes.
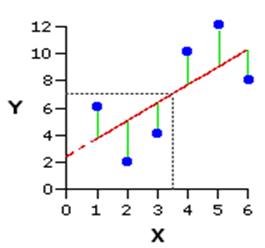
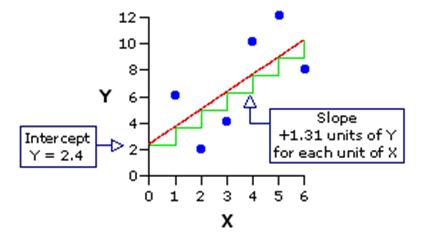
In regression it is convenient to define X as the explanatory (or predictor/independent) variable and Y as the outcome (or dependent) variable. We are concerned with determining how well X can predict Y. It is important to know which variable is the outcome (Y) and which is the explanatory variable (X)! This may sound obvious but in education research it is not always clear - for example does greater interest in reading predict better reading skills? Possibly. But it may be that having better reading skills encourages greater interest in reading. Education research is littered with such 'chicken and egg' arguments! Make sure that you know what your hypothesis about the relationship is when you perform a regression analysis as it is fundamental to your interpretation. Let's try and visualise how we can make a prediction using a scatterplot:
We will have a go at using SPSS/PASW to perform a linear regression soon but first we must consider some important assumptions that need to be met for simple linear regression to be performed. |