Using Statistical Regression Methods in Education Research

Extension A: What should I do if my continuous variables are not normally distributed?
|
There are occasions where your continuous variables may not be normally
distributed. This is often caused by ceiling or floor
effects
where data points gather at the extremes of the scale but it can occur for a great many reasons. This can lead to many a researcher tantrum – after all, doesn’t this mean that regression analysis cannot be used? In actual fact this is not always the case as sometimes non-normal data can be sensibly ‘transformed’. For an
example
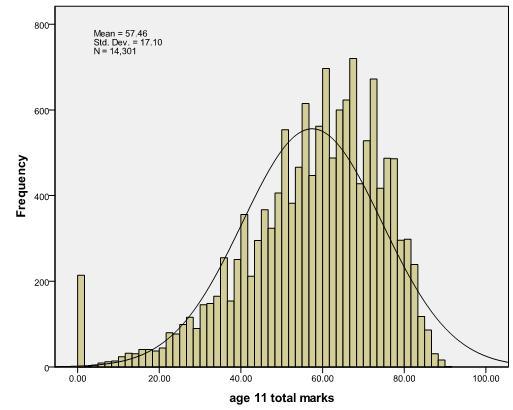
let’s plot a histogram of age 11 exam scores (KS2score), complete with a superimposed normal
curve (Figure A1). If you like, you can follow us through this process using the LSYPE 15,000 Figure A1: Histogram of KS2 score
Let’s take a close look at our histogram. Two things are notable about the distribution:
This non-normal distribution is a significant problem if we want to use parametric statistical tests with our data, since these methods assume normally distributed continuous variables. What can we do about this? Luckily SPSS has a number of options to transform scores in situations where the distribution is not normal.
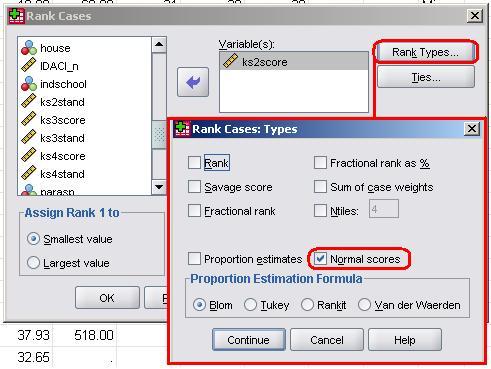
In this section we will transform our ks2 score to the normal equivalent. From the menu you would do this as follows: Transform -> Rank. You will get the window shown below. Click on Rank types and you will get another pop-up box where you should check the box marked Normal scores. The other options do not need to be altered so just click Continue and then OK on the main window...
SYNTAX ALERT!!!
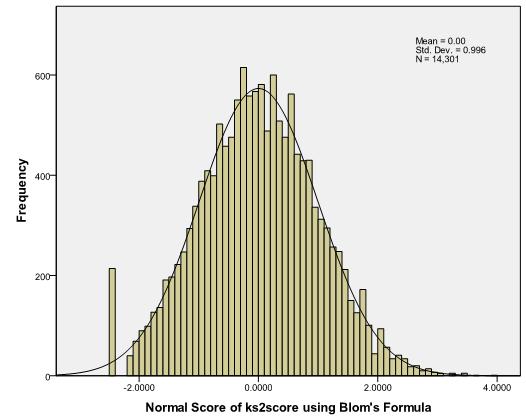
You could also do this using the following syntax, if you are so inclined: RANK VARIABLES=kS2score (A) /NORMAL This creates a new variable prefixed by N to indicate normalised, so here the new variable is called NkS2scor. Let’s plot a histogram of Nks2scor to examine its distribution (use the same SPSS commands as before, just swap the variable): Figure A2: Histogram of the transformed variable (Nks2scor)
Compare Figure A2 with Figure A1. See how much it has changed? We now have a distribution that is very close to the normal distribution. In essence the transformation has ranked the scores, calculated the proportion of cases at each rank, and applied the Z score that equates to that proportion based on the normal distribution (e.g. cases at the 50th percentile will have a score of 0, cases at the 84th percentile a score of 1, cases at the 95th percentile a score of 1.64 etc). It is not important to know exactly how this transformation is calculated, but something called the BLOM formula calculates the proportions. There is still the peak at the bottom of the distribution representing those students who were performing below the level assessed by the tests, but we will live with this for the reasons described earlier – these individuals constitute an important group and excluding them would bias our findings.
This new variable has a mean of 0 and standard deviation of 1. However for the purposes of our examples it will be easier to work with larger numbers without decimal places, so we will just multiply Nks2scor by 10 and round the figures up to create a new variable called ks2stand (the Key Stage 2 standard mark). You already have this in your dataset so don’t worry too much about adding these additional changes!
There are a range of other transformations that can be used to correct non-normal data distributions. While many students are (understandably) suspicious of such transformations (it sounds like fudging or fixing your data!) the key principle is that you apply the same transformation to all your data points. We don’t intend to go through all the transformations here, but a good transformation should be a relatively simple and straightforward operation. For example a square root transformation is often use when the outcome data (for example income) might be positively skewed (for example by having a small number of very high salaries for millionaires). Taking the square root of large values has more of an impact than taking the square root of small values. Consequently taking the square root of your data points will bring any large scores closer to the centre. Other common transformations include taking the log [log(x)] or the reciprocal [1/x] of your data. See Field, 2009 (p153-164) for a detailed discussion of transformation of data.
...However, if you want to learn more about computing variables here is a brief guide to how we did it. Transform > Compute Variable will open up the Compute pop-up menu.
We need to type the name of our new variable into the small window in the top left called Target Variable. We have called it ks2stand2 for the purposes of this demonstration because we already have the ks2stand2 variable saved! Our aim is to multiply the variable by 10 and round it to the nearest full number. From the Function group window on the far right select Arithmetic and then Rnd(1) from the Functions and Special Variables window just below it. RND(?) will appear in the Numeric Expression window at the top. The long window on the left contains all of our variables – pull the newly created Nks2score in to the expression (it will replace the question mark). To multiply it by 10 simply use the numeric pad in the middle of the pop-up menu (or the one on your keyboard) to add ‘*10’. Finally we need to complete the expression by telling SPSS how many decimal places we want our score rounded to. Simply place a coma followed by ‘1’ to tell SPSS we want the nearest whole number (if we wanted 1 decimal place we would put 0.1, two decimal places 0.01, etc.). Once you are happy with your expression click OK to create the new variable! SYNTAX ALERT!!! The descriptive statistics for ks2stand are shown below (Figure A3). The mean score is still 0 but the standard deviation is now 10, and the scores range from -24 to 39. The previous histogram (Figure A2) below shows the distribution of scores. Figure A3: Descriptive statistics for ks2 standardised score
We have followed the same process as described above to create transformed variables for age 14 standard score (ks3stand) and age 16 standard score (ks4stand). You will find these in the data file. As an optional exercise follow the example above to transform ks3score to the normal score equivalent. Does your transformed variable have the same distribution as the variable ks3stand in the file? Check your answer here! |
 data set: Graphs >
Legacy Dialogs > Histograms. When you get the pop-up menu, move the
data set: Graphs >
Legacy Dialogs > Histograms. When you get the pop-up menu, move the