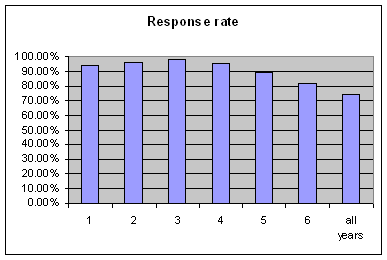
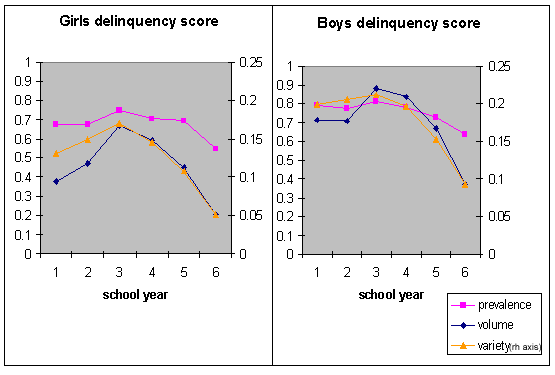
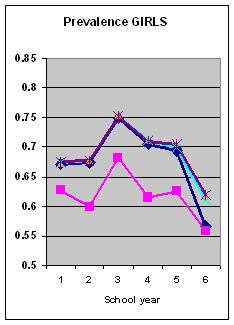
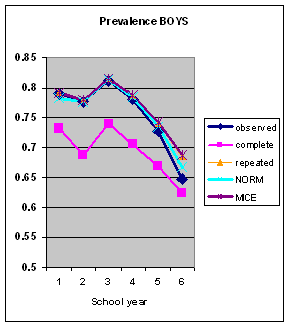
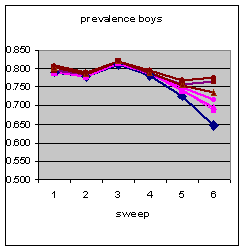
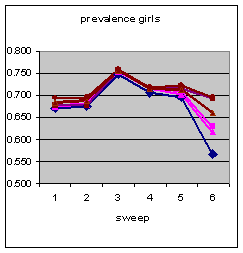
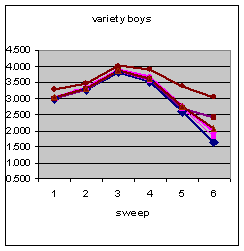
| |
Variable |
Label |
| 39 |
YAYARS01 |
YA Ever set fire to
something
|
| 21 |
YAYBOP01 |
YA Ever rowdy or rude in public |
| 17 |
YAYBUS01 |
YA Ever dodged paying correct fare |
| 43 |
YAYCBK01 |
YA Ever broken into a vehicle to
steal
|
| 33 |
YAYGRF01 |
YA Ever written or sprayed
graffiti
|
| 31 |
YAYHBK01 |
YA Ever broken into a house or
building
|
| 41 |
YAYHIT01 |
YA Ever hit, kicked or punched
someone
|
| 37 |
YAYHOM01 |
YA Ever stolen something from home |
| 23 |
YAYJRD01 |
YA Ever stolen/ridden in a stolen vehicle |
| 35 |
YAYROB01 |
YA Ever used force/threats/weapon |
| 25 |
YAYSCL01 |
YA Ever stolen something from
school
|
| 19 |
YAYSHP01 |
YA Ever stolen from a shop |
| 45 |
YAYSKV01 |
YA Ever skived school |
| 29 |
YAYVND01 |
YA Ever vandalised property |
| 27 |
YAYWEP01 |
YA Ever carried a knife or weapon |
| 94 |
YBYARS01 |
YB Set fire to something in last
year
|
| 76 |
YBYBOP01 |
YB Noisy or cheeky in public in last
ye
|
| 72 |
YBYBUS01 |
YB Dodged paying correct fare in last
y
|
| 98 |
YBYCBK01 |
YB Broken into a vehicle to steal in
la
|
| 88 |
YBYGRF01 |
YB Wrote or sprayed graffiti in last
ye
|
| 86 |
YBYHBK01 |
YB Broken into a house or building to
s
|
| 96 |
YBYHIT01 |
YB Hit, kicked or punched someone in
la
|
| 92 |
YBYHOM01 |
YB Stolen something from home in last
y
|
| 78 |
YBYJRD01 |
YB Ridden in a stolen vehicle in last
y
|
| 90 |
YBYROB01 |
YB used force/threats/weapon to rob
so
|
| 80 |
YBYSCL01 |
YB Stolen something from school in
last
|
| 74 |
YBYSHP01 |
YB Stolen something from a shop in
last
|
| 100 |
YBYSKV01 |
YB Skived school in last year |
| 84 |
YBYVND01 |
YB Vandalised property in last
year
|
| 82 |
YBYWEP01 |
YB Carried a knife or weapon in last
ye
|
| 152 |
YCYARS01 |
YC: Set fire to something in last
year
|
| 134 |
YCYBOP01 |
YC: Noisy or cheeky in public in last
ye
|
| 130 |
YCYBUS01 |
YC: Dodged paying correct fare in last
y
|
| 156 |
YCYCBK01 |
YC: Broken into a vehicle to steal in
la
|
| 162 |
YCYDRG01 |
YC: Sold an illegal drug in last
year
|
| 146 |
YCYGRF01 |
YC: Wrote or sprayed graffiti in last
ye
|
| 144 |
YCYHBK01 |
YC: Broken into a house or building to
s
|
| 154 |
YCYHIT01 |
YC: Hit, kicked or punched someone in
la
|
| 150 |
YCYHOM01 |
YC: Stolen something from home in last
y
|
| 136 |
YCYJRD01 |
YC: Ridden in a stolen vehicle in last
y
|
| 160 |
YCYPET01 |
YC: Cruel to animals/birds in last
year
|
| 164 |
YCYRAB01 |
YC: Racially abused someone in last
year
|
| 148 |
YCYROB01 |
YC: Used force/threats/weapon to rob
some
|
| 138 |
YCYSCL01 |
YC: Stolen something from school in
last
|
| 132 |
YCYSHP01 |
YC: Stolen something from a shop in
last
|
| 158 |
YCYSKV01 |
YC: Skived school in last year |
| 142 |
YCYVND01 |
YC: Vandalised property in last
year
|
| 140 |
YCYWEP01 |
YC: Carried a knife or weapon in last
ye
|
| 219 |
YDYARS01 |
YD: Set fire to something in last
year
|
| 201 |
YDYBOP01 |
YD: Noisy or cheeky in public in the
last year
|
| 197 |
YDYBUS01 |
YD: Dodged paying correct fare in last
y
|
| 223 |
YDYCBK01 |
YD: Broken into vehicle to steal in
last
|
| 229 |
YDYDRG01 |
YD: Sold an illegal drug in last
year
|
| 213 |
YDYGRF01 |
YD: Wrote or sprayed graffiti in last
year
|
| 211 |
YDYHBK01 |
YD: Broken into house\building to
steal
|
| 221 |
YDYHIT01 |
YD: Hit, kicked, punched someone in
last year
|
| 217 |
YDYHOM01 |
YD: Stolen something from home in last
year
|
| 203 |
YDYJRD01 |
YD: Ridden in stolen vehicle in the
last year
|
| 227 |
YDYPET01 |
YD: Cruel to animals\birds in last
year
|
| 231 |
YDYRAB01 |
YD: Racially abused someone in last
year
|
| 215 |
YDYROB01 |
YD: Used force\threats\weapon in last
ye
|
| 205 |
YDYSCL01 |
YD: Stolen something from school in
last
|
| 199 |
YDYSHP01 |
YD: Stolen something from shop in last
y
|
| 225 |
YDYSKV01 |
YD: Skived school in last year |
| 209 |
YDYVND01 |
YD: Vandalised property in last
year
|
| 207 |
YDYWEP01 |
YD: Carry knife or weapon in last
year
|
| 267 |
YEYWEP01 |
YE: Carry knife or weapon in last
year
|
| 332 |
YFYARS01 |
YF: Set fire to something in last
year
|
| 350 |
YFYBFT01 |
YF: Claimed benefits not entitled to
in
|
| 320 |
YFYBOP01 |
YF: Noisy or cheeky in public in the
las
|
| 336 |
YFYCBK01 |
YF: Broken into vehicle to steal in
last
|
| 342 |
YFYDRG01 |
YF: Sold an illegal drug in last
year
|
| 352 |
YFYFRD01 |
YF: Cheque, credit fraud etc, in last
ye
|
| 328 |
YFYHBK01 |
YF: Broken into house\building to
steal
|
| 334 |
YFYHIT01 |
YF: Hit, kicked,punched someone in
last y
|
| 322 |
YFYJRD01 |
YF: Ridden in stolen vehicle, ever
done
|
| 340 |
YFYPET01 |
YF: Cruel to animals\birds in last
year
|
| 344 |
YFYRAB01 |
YF: Racial abuse, ever done it |
| 330 |
YFYROB01 |
YF: Robbed person of property in last
ye
|
| 346 |
YFYRST01 |
YF: Sold on stolen property in last
year
|
| 348 |
YFYRST21 |
YF: Bought stolen property in last
year
|
| 349 |
YFYRST22 |
YF: Bought stolen property, times done
i
|
| 318 |
YFYSHP01 |
YF: Stolen something from shop in last
y
|
| 338 |
YFYSKV01 |
YF: Skived school in last year |
| 326 |
YFYVND01 |
YF: Vandalised property in last
year
|
| 324 |
YFYWEP01 |
YF: Carry knife or weapon in last
year
|
 multiple
imputations
multiple
imputations