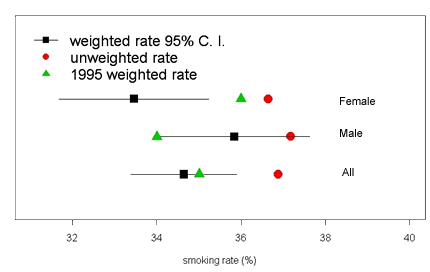
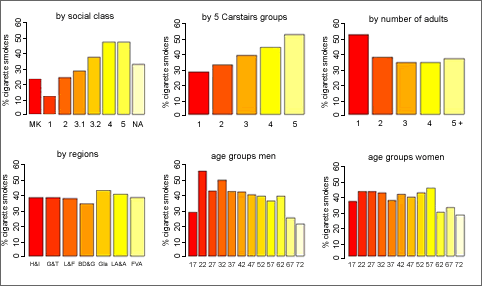
top
The Scottish Health Survey is a survey of the
household population of Scotland. Fieldwork for the 1998
survey took place over the year in a manner that balanced the
sample for seasonal features. The survey includes an
interview and a visit from a nurse. We will only be using the
interview data. One adult per household, randomly chosen, is
interviewed. The sampling frame used was the postcode address
file (
 PAF). This survey also includes data on children, but
we do not include them in analyses here.
PAF). This survey also includes data on children, but
we do not include them in analyses here.
The primary sampling units were post code
sectors (around 5000 households). The PSUs were selected with
probability proportional to size, with some exceptions in the
Island areas, that are discussed in the technical report of
the survey. A sample of 46 addresses was then selected from
each selected PSU. In the last quarter of the year this
number was increased to 58.
The selection of postcode sectors was carried
out separately within each region. Regions of Scotland were
either individual Health Boards or pairs of Health Boards.
Within each Region the sectors were ordered by their
Carstairs deprivation index and a systematic sample was
selected. This means that the sample is implicitly stratified
by the Carstairs index, since the balance in the sample will
reflect the pattern in the sampling frame. To represent this
in the design, strata have been formed by grouping adjacent
sectors (with similar Carstairs values) together in pairs to
form strata. A few strata contained 3 PSUs because of odd
numbers.
The probability of selection for a PSU varied
by region. Also a weight equal to the number of adults in the
household was applied to adjust for the over-representation
of people in households with few adults.
After the survey data were completed and the
design weights calculated the achieved weighted sample was
compared to the mid year population estimates in terms of its
regional distribution and age/sex categories. A further
weight was calculated to make the sample match the population
data. This effectively adjusts for differential non-response
by region and by age and sex. Response was lowest in Glasgow
and among the age groups 20-35.
The final weights are a combination of the
design weights and the
post-stratification weights. The
histogram below shows the distribution of the variable
WEIGHTA, it is scaled to add (approximately) to the sample
size.
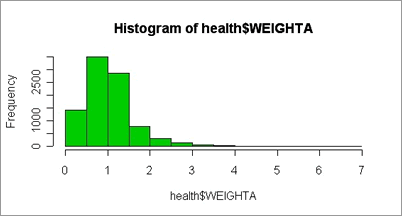
Fig 3.3: Histogram of final weights
scaled to add to sample size.
A further weight is provided on our data
files. This is called GROSSWT and is identical to WEIGHTA
except that it has been scaled up to make its total match the
mid year population estimate for 16-74 year olds in Scotland.
It is required by SPSS in order to get estimates of Design
Effects.
We have constructed a data set for this
analysis with just those variables we will use. The process
by which the data set has been constructed and the
programmes used to make it from data at Essex data archive)
are explained in detail here for anyone who has an interest in
this . The identification of the PSUs from the data on the
archive required some detective work. It is explained in the
comments of the SPSS program used to prepare the data set.
After the PSUs had been identified they were
grouped into strata in pairs according to the ranking of
their Carstairs index, within regions. Where there were an
odd number of PSUs in a region the last stratum was given 3
PSUs.
The information used to derive this
information, including the exact Carstairs index values of
the PSUs, has been removed from the file to prevent
identification.
The variables in the data files are :-
|
Variable |
Label |
| 1 |
age |
age of respondent in
questionnaire.
|
| 2 |
sex |
sex of respondent from household
grid.
|
| 3 |
hboard |
Health Board |
| 4 |
carstg5 |
carstairs index |
| 5 |
cigst1 |
cigarette smoking
status-never/ex-reg/ex-occ/current
|
| 6 |
cigst2 |
cigarette smoking status - banded
current smokers
|
| 7 |
nofad |
number of adults |
| 8 |
sc |
social class (adult
respondent)
|
| 9 |
weighta |
weight variable (with some random
noise added)
|
| 10 |
grosswt |
weight grossed to population
totals
|
| 11 |
idno |
sequential ID |
| 12 |
psu |
PSU no |
| 13 |
regstrat |
unique stratum no |
|